Reflections on an altruist’s suicide
George Price was a theoretical biologist who committed suicide after haven given all his possessions to the poor. Why you ask? Because he could not deal with the fact that:
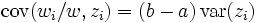
One wonders what might have been so terrible about this formula that the man who through his work provided a general way in which to measure the direction and speed of any selection process would felt compelled to kill himself.
Examining the background one uncovers a truly tragic story. For the reason Price started dabbling in the field of theoretical biology in the first place lies in the circumstance that after stumbling over a set of equations that were discovered ten years earlier by William Hamilton he was so disturbed by them that he attempted to disprove them. Yet instead of disproving them he ended up reworking them into a more elegant form and for wider application.
Price had reformulated a set of mathematical equations that show that altruism can prosper in a world where it seems that only selfishness is rewarded. While he showed that true self sacrificing behavior can exist among animals and humans he also proved that there was nothing noble about it – altruism merely is an evolutionary stable strategy. When his work was completed he went mad.
I can empathize with the longing for goodness in the absence of a reason for doing good. How selfless is it to give something only to expect something in return? Are we not touched by stories of self sacrifice and bravery – gallantry and noblesse? Sure we are – exactly because of said equation we evolved to feel that way.
We have evolved to feel warm and fuzzy when we give something without expecting something in return because it increased our fitness. We are fitter because of it. Proving that mathematically would have filled me with great joy. Knowing that one has to do good to others in order to avoid going extinct. By knowing and understanding the altruism equation one can free oneself from having to belief in a fuzzy difficult to grasp concept of goodness without justification and can embrace the mathematical inevitability.
People are not punished for their sins but by their sins in the absence of everything except the mathematical proof. How great is that? It is not only good to do good but it is advantageous – don’t do it and go extinct. Who wants to argue with that?
Follow up 2007/11/12: Having reflected more on Price’s equations it turns out that the implications of the Price equation are further reaching then I initially understood them. For not only is it beneficial to cooperate and be what is conventionally called ‘altruistic’ but egoism is just as viable a strategy and depending on the pay-offs will result in an evolutionary equilibrium of altruists as well as egoists. More here.